
Or "How I've halved the execution time of our tests by removing ten lines".
Catchy, huh? Also not
exactly true, but quite close. Enjoy!
Molecule?!
"
Molecule project is designed to aid in the development and testing of Ansible roles."
No idea about the development part (I have
vim and
mkdir), but it's really good for integration testing.
You can write different
test scenarios where you define an environment (usually a container), a playbook for the execution and a playbook for verification.
(And a lot more, but that's quite unimportant for now, so go read the docs if you want more details.)
If you ever used
Beaker for Puppet integration testing, you'll feel right at home (once you've thrown away Ruby and DSLs and embraced YAML for everything).
I'd like to point out one thing, before we continue.
Have another look at the quote above.
"Molecule project is designed to aid in the development and testing of Ansible roles."
That's right.
The project was
started in 2015 and was always about
roles.
There is nothing wrong about that, but given the Ansible world has moved on to collections (which can contain roles), you start facing challenges.
Challenges using Ansible Molecule in the Collections world
The biggest challenge didn't change since the last time I looked at the topic in 2020:
running tests for multiple roles in a single repository ("monorepo") is tedious.
Well, guess what a collection is?
Yepp, a repository with multiple roles in it.
It did get a bit better though.
There is
pytest-ansible now, which has
integration for Molecule.
This allows the execution of Molecule and even provides reasonable logging with something as short as:
% pytest --molecule roles/
That's much better than the shell script I used in 2020!
However, being able to execute tests is one thing.
Being able to execute them
fast is another one.
Given Molecule was initially designed with single roles in mind, it has switches to run all scenarios of a role (
--all), but it has no way to run these in parallel.
That's fine if you have one or two scenarios in your role repository.
But what if you have 10 in your collection?
"No way?!" you say after quickly running
molecule test --help, "But there is "
% molecule test --help
Usage: molecule test [OPTIONS] [ANSIBLE_ARGS]...
--parallel / --no-parallel Enable or disable parallel mode. Default is disabled.
Yeah, that switch exists, but it
only tells Molecule to place things in separate folders, you still need to parallelize yourself with GNU parallel or pytest.
And here our actual journey starts!
Running Ansible Molecule tests in parallel
To run Molecule via
pytest in parallel, we can use
pytest-xdist, which allows
pytest to run the tests in multiple processes.
With that, our
pytest call becomes something like this:
% MOLECULE_OPTS="--parallel" pytest --numprocesses auto --molecule roles/
What does that mean?
MOLECULE_OPTS passes random options to the Molecule call pytest does, and we need to add --parallel there.--numprocesses auto tells pytest-xdist to create as many workers as you have CPUs and balance the work across those.
However, once we actually execute it, we see:
% MOLECULE_OPTS="--parallel" pytest --numprocesses auto --molecule roles/
WARNING Driver podman does not provide a schema.
INFO debian scenario test matrix: dependency, cleanup, destroy, syntax, create, prepare, converge, idempotence, side_effect, verify, cleanup, destroy
INFO Performing prerun with role_name_check=0...
WARNING Retrying execution failure 250 of: ansible-galaxy collection install -vvv --force ../..
ERROR Command returned 250 code:
OSError: [Errno 39] Directory not empty: 'roles'
FileExistsError: [Errno 17] File exists: b'/home/user/namespace.collection/collections/ansible_collections/namespace/collection'
FileNotFoundError: [Errno 2] No such file or directory: b'/home/user/namespace.collection//collections/ansible_collections/namespace/collection/roles/my_role/molecule/debian/molecule.yml'
You might see other errors, other paths, etc, but they all will have one in common: they indicate that either files or directories are present, while the tool expects them not to be, or vice versa.
Ah yes, that fine smell of race conditions.
I'll spare you the wild-goose chase I went on when trying to find out what the heck was calling
ansible-galaxy collection install here.
Instead, I'll just point at the following line:
INFO Performing prerun with role_name_check=0...
What is this "prerun" you ask?
Well
"To help Ansible find used modules and roles, molecule will perform a prerun set of actions. These involve installing dependencies from requirements.yml specified at the project level, installing a standalone role or a collection."
Turns out, this step is not
--parallel-safe (yet?).
Luckily, it can easily be disabled, for all our roles in the collection:
% mkdir -p .config/molecule
% echo 'prerun: false' >> .config/molecule/config.yml
This works perfectly, as long as you don't have any dependencies.
And we don't have any, right?
We didn't define any in a
molecule/collections.yml, our collection has none.
So let's push a PR with that and see what our CI thinks.
OSError: [Errno 39] Directory not empty: 'tests'
Huh?
FileExistsError: [Errno 17] File exists: b'remote.sh' -> b'/home/runner/work/namespace.collection/namespace.collection/collections/ansible_collections/ansible/posix/tests/utils/shippable/aix.sh'
What?
ansible_compat.errors.InvalidPrerequisiteError: Found collection at '/home/runner/work/namespace.collection/namespace.collection/collections/ansible_collections/ansible/posix' but missing MANIFEST.json, cannot get info.
Okay, okay, I get the idea
But why?
Well, our collection might not have any dependencies, BUT MOLECULE HAS!
When using Docker containers, it uses
community.docker, when using Podman
containers.podman, etc
So we have to install those
before running Molecule, and everything should be fine.
We even can use Molecule to do this!
$ molecule dependency --scenario <scenario>
And with that knowledge, the patch to enable parallel Molecule execution on GitHub Actions using
pytest-xdist becomes:
diff --git a/.config/molecule/config.yml b/.config/molecule/config.yml
new file mode 100644
index 0000000..32ed66d
--- /dev/null
+++ b/.config/molecule/config.yml
@@ -0,0 +1 @@
+prerun: false
diff --git a/.github/workflows/test.yml b/.github/workflows/test.yml
index 0f9da0d..df55a15 100644
--- a/.github/workflows/test.yml
+++ b/.github/workflows/test.yml
@@ -58,9 +58,13 @@ jobs:
- name: Install Ansible
run: pip install --upgrade https://github.com/ansible/ansible/archive/$ matrix.ansible .tar.gz
- name: Install dependencies
- run: pip install molecule molecule-plugins pytest pytest-ansible
+ run: pip install molecule molecule-plugins pytest pytest-ansible pytest-xdist
+ - name: Install collection dependencies
+ run: cd roles/repository && molecule dependency -s suse
- name: Run tests
- run: pytest -vv --molecule roles/
+ run: pytest -vv --numprocesses auto --molecule roles/
+ env:
+ MOLECULE_OPTS: --parallel
ansible-lint:
runs-on: ubuntu-latest
But you promised us to delete ten lines, that's just a
+7-2 patch!
Oh yeah, sorry, the
+10-20 (so a net
-10) is the
foreman-operations-collection version of the patch, that also migrates from an ugly bash script to
pytest-ansible.
And yes, that cuts down the execution from ~26 minutes to ~13 minutes.
In the collection I originally tested this with, it's a more moderate "from 8-9 minutes to 5-6 minutes", which is still good though :)

 We are very excited to announce that Debian has selected seven contributors to work
under mentorship on a variety of
projects with us during the
Google Summer of Code.
Here are the list of the projects, students, and details of the tasks to be performed.
We are very excited to announce that Debian has selected seven contributors to work
under mentorship on a variety of
projects with us during the
Google Summer of Code.
Here are the list of the projects, students, and details of the tasks to be performed.
 My Debian contributions this month were all
My Debian contributions this month were all

 A short status update of what happened on my side last month. Maintenance
and code review keep to be the top time sinks (in a positive way).
A short status update of what happened on my side last month. Maintenance
and code review keep to be the top time sinks (in a positive way).

 The eleventh release of the
The eleventh release of the  It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
 With
With  I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
 I am upstream and
I am upstream and  Time really flies when
Time really flies when 

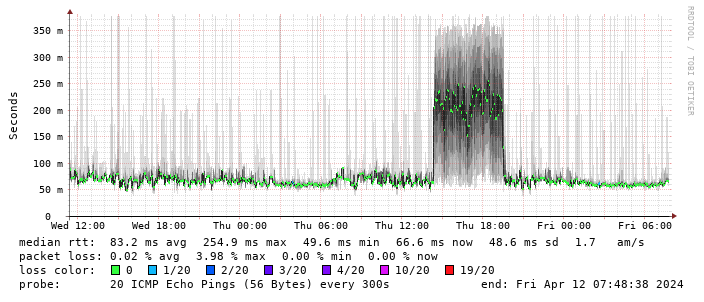 (There s a handy
(There s a handy 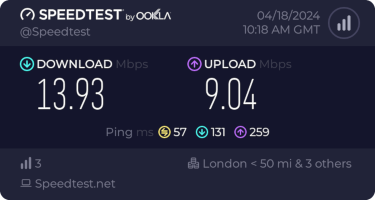 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
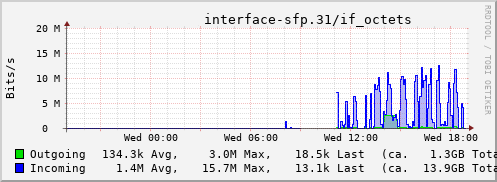 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
